Kandinsky 2.1
Architecture
Kandinsky 2.1 inherits best practicies from Dall-E 2 and Latent diffusion, while introducing some new ideas.
As text and image encoder it uses CLIP model and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
For diffusion mapping of latent spaces we use transformer with num_layers=20, num_heads=32 and hidden_size=2048.
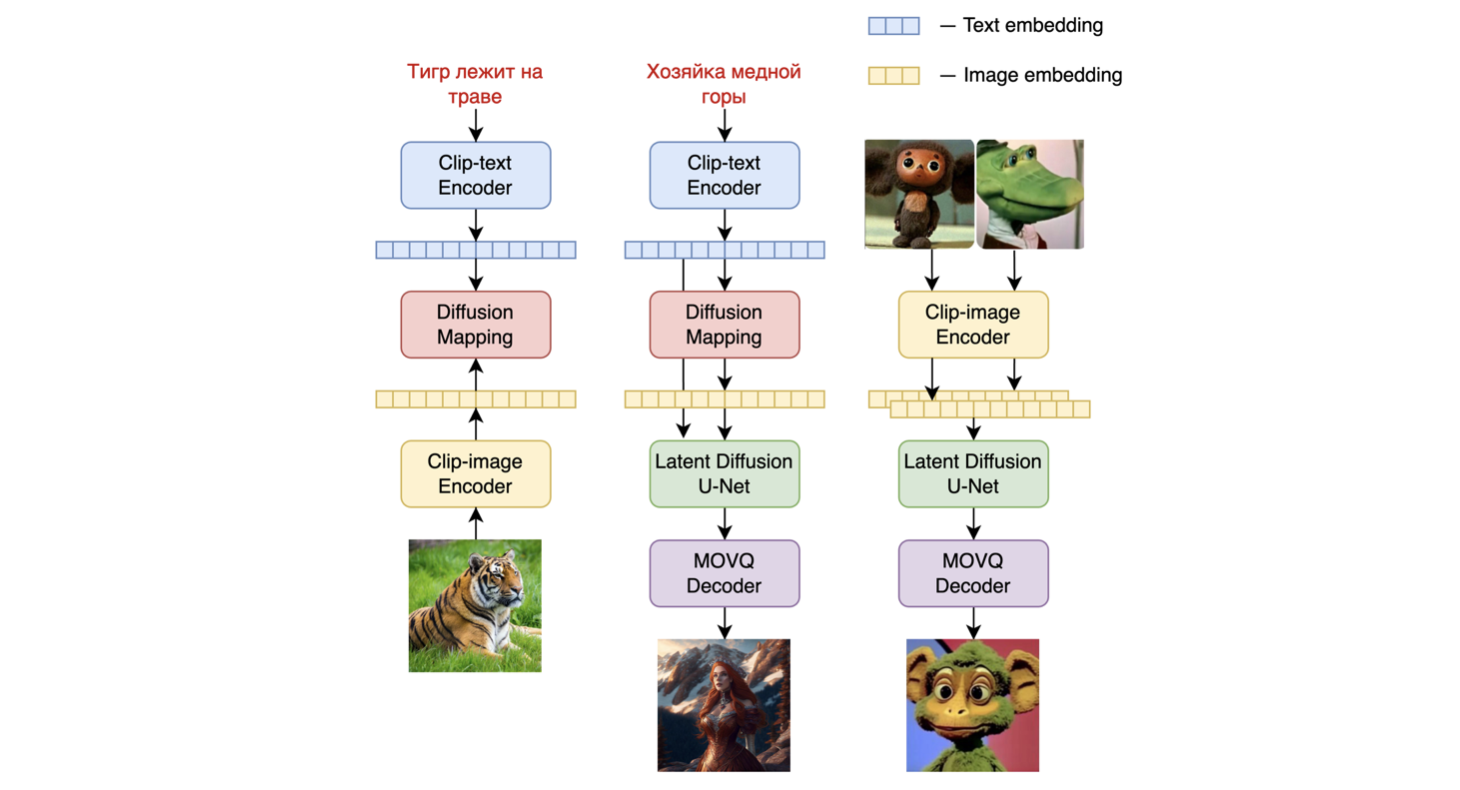
Other architecture parts:
- Text encoder (XLM-Roberta-Large-Vit-L-14) - 560M
- Diffusion Image Prior — 1B
- CLIP image encoder (ViT-L/14) - 427M
- Latent Diffusion U-Net - 1.22B
- MoVQ encoder/decoder - 67M



