German Electra Uncased
<img width="300px" src="https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png"> [¹]
Version 2 Release
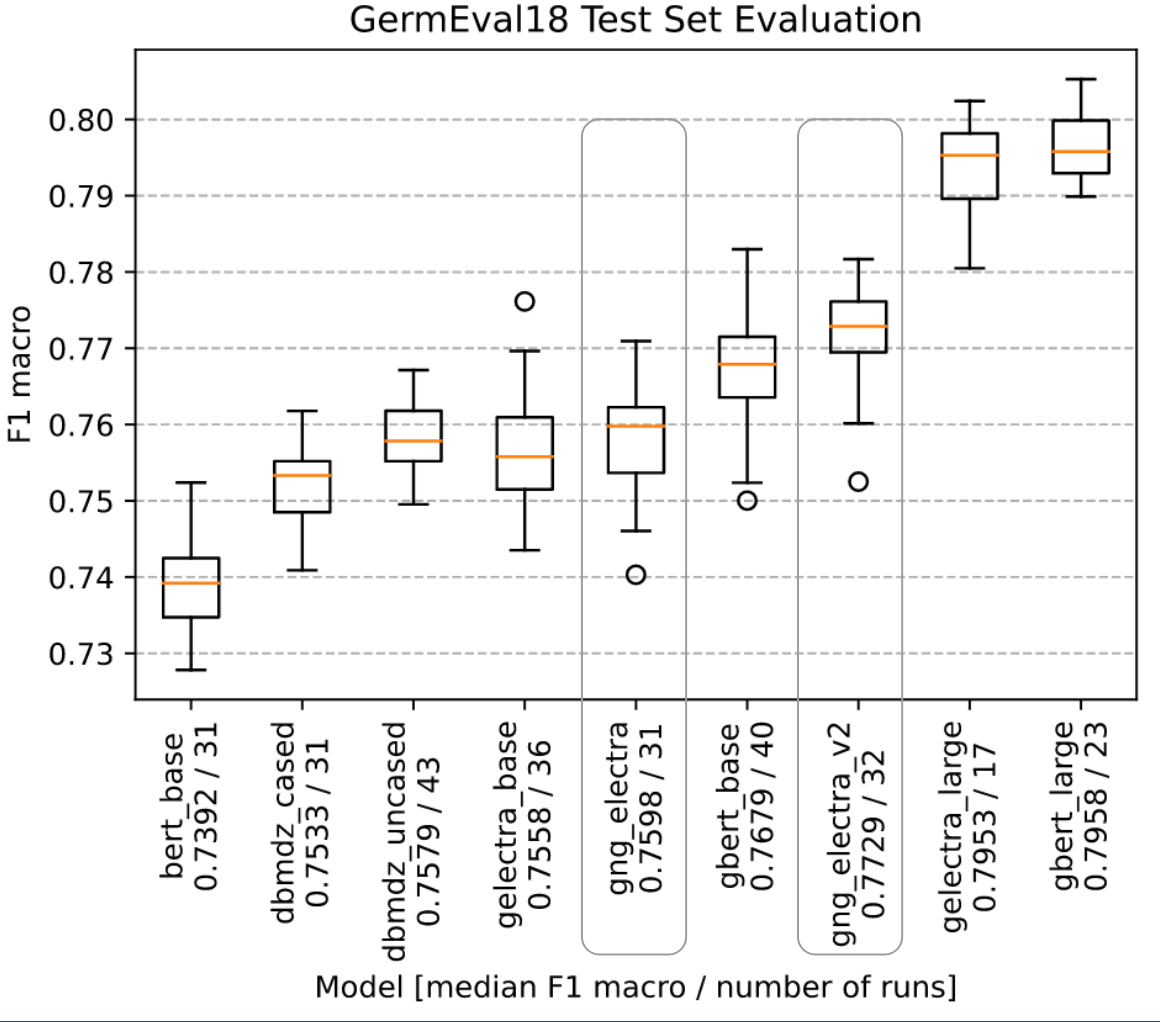
We released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See "Evaluation of Version 2: GermEval18 Coarse" below for details.
Model Info
This Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
It can be used as a drop-in replacement for BERT in most down-stream tasks (ELECTRA is even implemented as an extended BERT Class).
At the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
Installation
This model has the special feature that it is uncased but does not strip accents. This possibility was added by us with PR #6280. To use it you have to use Transformers version 3.1.0 or newer.
pip install transformers -U
Uncase and Umlauts ('Ö', 'Ä', 'Ü')
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
The special characters 'ö', 'ü', 'ä' are included through the strip_accent=False option, as this leads to an improved precision.
Creators
This model was trained and open sourced in conjunction with the German NLP Group in equal parts by:
Evaluation of Version 2: GermEval18 Coarse
We evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.
Checkpoint evaluation
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.
Pre-training details
Data
- Cleaned Common Crawl Corpus 2019-09 German: CC_net (Only head coprus and filtered for language_score > 0.98) - 62 GB
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
- Subtitles - 823 MB
- News 2018 - 4.1 GB
The sentences were split with SojaMo. We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).
More Details can be found here Preperaing Datasets for German Electra Github
Electra Branch no_strip_accents
Because we do not want to stip accents in our training data we made a change to Electra and used this repo Electra no_strip_accents (branch no_strip_accents). Then created the tf dataset with:
python build_pretraining_dataset.py --corpus-dir <corpus_dir> --vocab-file <dir>/vocab.txt --output-dir ./tf_data --max-seq-length 512 --num-processes 8 --do-lower-case --no-strip-accents
The training
The training itself can be performed with the Original Electra Repo (No special case for this needed). We run it with the following Config:
<details> <summary>The exact Training Config</summary> <br/>debug False <br/>disallow_correct False <br/>disc_weight 50.0 <br/>do_eval False <br/>do_lower_case True <br/>do_train True <br/>electra_objective True <br/>embedding_size 768 <br/>eval_batch_size 128 <br/>gcp_project None <br/>gen_weight 1.0 <br/>generator_hidden_size 0.33333 <br/>generator_layers 1.0 <br/>iterations_per_loop 200 <br/>keep_checkpoint_max 0 <br/>learning_rate 0.0002 <br/>lr_decay_power 1.0 <br/>mask_prob 0.15 <br/>max_predictions_per_seq 79 <br/>max_seq_length 512 <br/>model_dir gs://XXX <br/>model_hparam_overrides {} <br/>model_name 02_Electra_Checkpoints_32k_766k_Combined <br/>model_size base <br/>num_eval_steps 100 <br/>num_tpu_cores 8 <br/>num_train_steps 766000 <br/>num_warmup_steps 10000 <br/>pretrain_tfrecords gs://XXX <br/>results_pkl gs://XXX <br/>results_txt gs://XXX <br/>save_checkpoints_steps 5000 <br/>temperature 1.0 <br/>tpu_job_name None <br/>tpu_name electrav5 <br/>tpu_zone None <br/>train_batch_size 256 <br/>uniform_generator False <br/>untied_generator True <br/>untied_generator_embeddings False <br/>use_tpu True <br/>vocab_file gs://XXX <br/>vocab_size 32767 <br/>weight_decay_rate 0.01 </details>
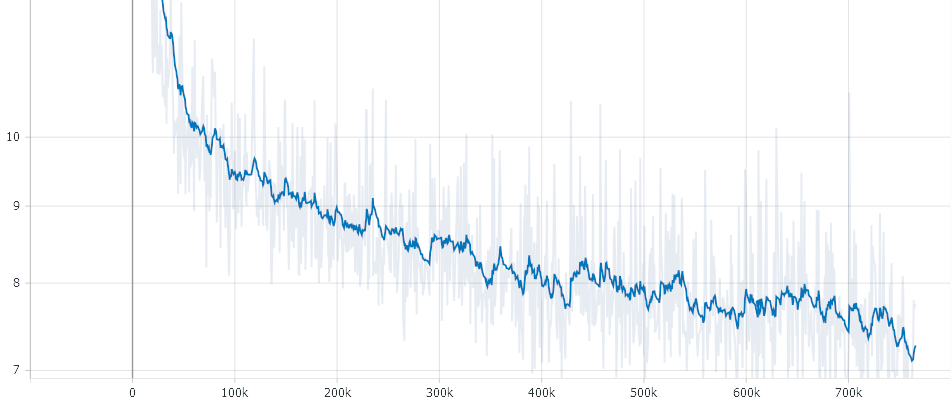
Please Note: Due to the GAN like strucutre of Electra the loss is not that meaningful
It took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used tpunicorn. The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by T-Systems on site services GmbH, ambeRoad. Special thanks to Stefan Schweter for your feedback and providing parts of the text corpus.
[¹]: Source for the picture Pinterest
Negative Results
We tried the following approaches which we found had no positive influence:
- Increased Vocab Size: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured
- Decreased Batch-Size: The original Electra was trained with a Batch Size per TPU Core of 16 whereas this Model was trained with 32 BS / TPU Core. We found out that 32 BS leads to better results when you compare metrics over computation time
License - The MIT License
Copyright 2020-2021 Philip May<br> Copyright 2020-2021 Philipp Reissel
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.