Model description
DeepMetal is a model capable of generating lyrics taylored for heavy metal songs. The model is based on the OpenAI GPT-2 and has been finetuned on a dataset of 141,718 heavy metal songs lyrics. More info about the project can be found in the official GitHub repository and in the related articles on my blog: part I, part II and part III.
Legal notes
Due to incertainity about legal rights, the dataset used for training the model is not provided. I hope you'll understand. The lyrics in question have been scraped from the website DarkLyrics using the library metal-parser.
Intended uses and limitations
The model is released under the Apache 2.0 license. You can use the raw model for lyrics generation or fine-tune it further to a downstream task. The model is capable to generate explicit lyrics. It is a consequence of a fine-tuning made with a dataset that contained such lyrics, which are part of the discography of many heavy metal bands. Be aware of that before you use the model, the author is not liable for any emotional response and following consequences.
How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, it could be good to set a seed for reproducibility:
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='lucone83/deep-metal', device=-1) # to use GPU, set device=<CUDA_device_ordinal>
>>> set_seed(42)
>>> generator(
"End of passion play",
num_return_sequences=1,
max_length=256,
min_length=128,
top_p=0.97,
top_k=0,
temperature=0.90
)
[{'generated_text': "End of passion play for you\nFrom the spiritual to the mental\nIt is hard to see it all\nBut let's not end up all be\nTill we see the fruits of our deeds\nAnd see the fruits of our suffering\nLet's start a fight for victory\nIt was our birthright\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call \nLike a typhoon upon your doorstep\nYou're a victim of own misery\nAnd the god has made you pay\n\nWe are the wolves\nWe will not stand the pain\nWe are the wolves\nWe will never give up\nWe are the wolves\nWe will not leave\nWe are the wolves\nWe will never grow old\nWe are the wolves\nWe will never grow old "}]
Of course, it's possible to play with parameters like top_k, top_p, temperature, max_length and all the other parameters included in the generate method. Please look at the documentation for further insights.
Here is how to use this model to get the features of a given text in PyTorch:
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('lucone83/deep-metal')
model = GPT2Model.from_pretrained('lucone83/deep-metal')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output_features = model(**encoded_input)
and in TensorFlow:
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('lucone83/deep-metal')
model = TFGPT2Model.from_pretrained('lucone83/deep-metal')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output_features = model(encoded_input)
Model training
The dataset used for training this model contained 141,718 heavy metal songs lyrics. The model has been trained using an NVIDIA Tesla T4 with 16 GB, using the following command:
python run_language_modeling.py \
--output_dir=$OUTPUT_DIR \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$VALIDATION_FILE \
--per_device_train_batch_size=3 \
--per_device_eval_batch_size=3 \
--evaluate_during_training \
--learning_rate=1e-5 \
--num_train_epochs=20 \
--logging_steps=3000 \
--save_steps=3000 \
--gradient_accumulation_steps=3
To checkout the code related to training and testing, please look at the GitHub repository of the project.
Evaluation results
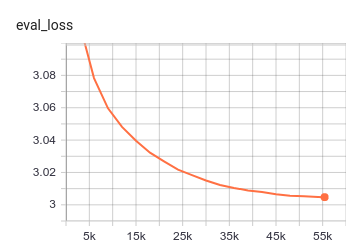
The model achieves the following results:
{
'eval_loss': 3.0047452173826406,
'epoch': 19.99987972095261,
'total_flos': 381377736125448192,
'step': 55420
}
perplexity = 20.18107365414611