bert-large-uncased-Fake_Reviews_Classifier
This model is a fine-tuned version of bert-large-uncased.
It achieves the following results on the evaluation set:
- Loss: 0.5336
- Accuracy: 0.8381
- F1
- Weighted: 0.8142
- Micro: 0.8381
- Macro: 0.6308
- Recall
- Weighted: 0.8381
- Micro: 0.8381
- Macro: 0.6090
- Precision
- Weighted: 0.8101
- Micro: 0.8381
- Macro: 0.7029
Model description
For more information on how it was created, check out the following link: https://github.com/DunnBC22/NLP_Projects/blob/main/Binary%20Classification/Fake%20Reviews/Fake%20Reviews%20Classification%20-%20BERT-Large%20With%20PEFT.ipynb
Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology. You are welcome to test and experiment with this model, but it is at your own risk/peril.
Training and evaluation data
Dataset Source: https://www.kaggle.com/datasets/razamukhtar007/fake-reviews
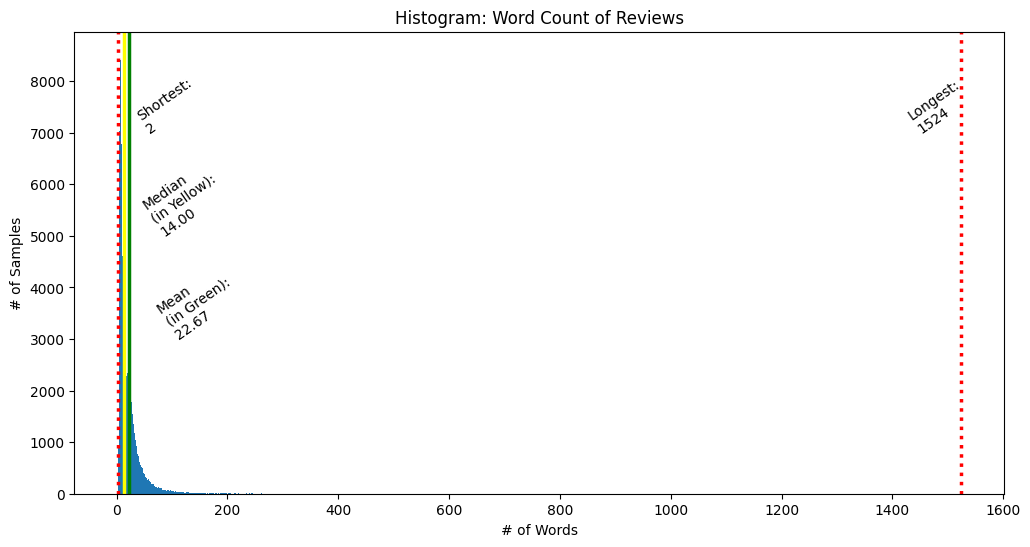
Histogram of Word Counts of Reviews
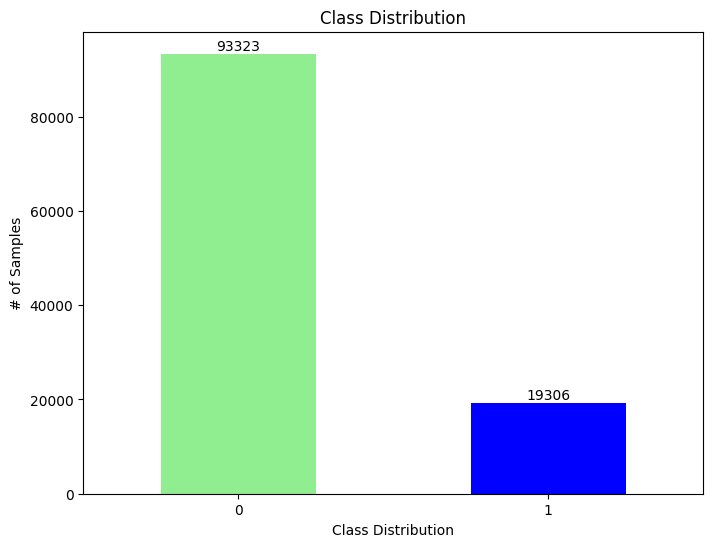
Class Distribution
Training procedure
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Weighted F1 | Micro F1 | Macro F1 | Weighted Recall | Micro Recall | Macro Recall | Weighted Precision | Micro Precision | Macro Precision |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.633 | 1.0 | 10438 | 0.5608 | 0.8261 | 0.7914 | 0.8261 | 0.5745 | 0.8261 | 0.8261 | 0.5643 | 0.7844 | 0.8261 | 0.6542 |
| 0.6029 | 2.0 | 20876 | 0.6490 | 0.8331 | 0.7724 | 0.8331 | 0.5060 | 0.8331 | 0.8331 | 0.5239 | 0.7892 | 0.8331 | 0.6929 |
| 0.5478 | 3.0 | 31314 | 0.5508 | 0.8305 | 0.8071 | 0.8305 | 0.6189 | 0.8305 | 0.8305 | 0.6003 | 0.8002 | 0.8305 | 0.6784 |
| 0.513 | 4.0 | 41752 | 0.5459 | 0.8347 | 0.8101 | 0.8347 | 0.6224 | 0.8347 | 0.8347 | 0.6023 | 0.8049 | 0.8347 | 0.6916 |
| 0.5288 | 5.0 | 52190 | 0.5336 | 0.8381 | 0.8142 | 0.8381 | 0.6308 | 0.8381 | 0.8381 | 0.6090 | 0.8101 | 0.8381 | 0.7029 |
Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1
- Datasets 2.13.1
- Tokenizers 0.13.3


