Ashhwriter-Mistral-7B (v1)
<!-- Provide a quick summary of what the model is/does. -->
A text completion model trained on about 315 MB of relatively narrow-focused amateur erotica broken into chunks of about 8k tokens length, based on Mistral-7B-0.1.
Please note that this is not a chat model nor an instruct model! Further finetuning will be needed for that.
Available versions
- Float16 HF
- LoRA adapter (adapter_model.bin and adapter_config.json)
- Q6_K GGUF quantization
- AWQ (4 bits, 128g)
Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
The model can be used as-is, or merged with other ones (preferably using the provided LoRA adapter) to give them a very strong NSFW and potentially shocking bias. It could also be used as a finetuning base for chat models.
It has no specific prompting format as it's been trained in a form close to true unsupervised finetuning. <!--However, a large portion of the training samples had a header that included general information following this template (without curly braces):
{brief indications on what the model should be writing next}
Title: {story title here}
Story codes: {asstr-based story codes}
Synopsis: {a very brief overview of what happens in the story}
Source: {the website from which the story originated}
-----
{story output here}
``` -->
### Some prompting tips for text autocompletion
- In KoboldAI/KoboldLite, using `<s>` (BOS token) as the first token
in the context window may improve generation quality. _This does not work with the GGUF
version_.
- The separator `-----` <!-- that was used in the template above (or other fixed portions
of the template) --> may trigger the model into completing text in a style closer to that used
during training.
- It appears that, at least when testing in text-generation-webui, leaving an empty
line at the beginning of the context can make the outputs more aligned to the finetune.
- Enclosing dialogues in quotation marks makes the model draw more from its storywriting
background.
### Unusually effective prompting templates
Although the model hasn't been trained on instructions or chat data, formatting
questions as a signed letter can work well in getting a long reasoned response.
{your question here}
{signature}
{model response}
Using a Question/Answer format may also work. It can be beneficial to add indications
regarding the style.
Q: {your question here}. Please be detailed and informative.
A: {model response}
## Bias, Risks, and Limitations
## Bias and Risks
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
From practical observations, the model will very easily produce offensive, harmful and even
dangerous hallucinations of _any kind_, surprisingly not limiting to what was included
in the source dataset.
The source dataset includes fictional content that many could find shocking and
disturbing. The model outputs will often reflect this bias.
## Limitations
The model was **not** designed for the following uses:
- Question answering
- Instruction following
- Adventure mode
- Chatting / Roleplaying
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Due to the nature of the content it can generate, it is strongly advised not to use the
model in public-facing environments, where a general audience is expected, or by minors.
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The data used for training is available from public sources and **will not be provided
on or via Huggingface**. In total, about 315 MB of data have been used.
A basic cleaning procedure was performed for normalizing punctuation (at least to some
extent) and converting HTML tags when present, but no particular effort was made to remove
story milestones, trailers and acknowlegments when they were not clearly separated from
the story. In some cases chapter titles have been surrounded by `===` or `=====`, but not
all of them have this format.
Excessively short (500 tokens or less) stories or story chunks have been rejected, and
a very basic check was performed to reject _most_ non-English stories as well.
### Training procedure
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
on 2x NVidia A40 GPUs.
The A40 GPUs have been graciously provided by [Arc Compute](https://www.arccompute.io/).
### Training hyperparameters
A lower learning rate than usual seemed necessary for this dataset.
Noisy embeddings (NEFT) were used for training; actual impact unknown.
- learning_rate: 0.000055
- lr_scheduler: constant_with_warmup
- noisy_embedding_alpha: 5
- num_epochs: 2
- sequence_len: 8192
- lora_r: 256
- lora_alpha: 16
- lora_dropout: 0.0
- lora_target_linear: True
- bf16: True
- fp16: false
- tf32: True
- load_in_8bit: True
- adapter: lora
- micro_batch_size: 2
- gradient_accumulation_steps: 1
- warmup_steps: 100
- optimizer: adamw_bnb_8bit
- flash_attention: true
- sample_packing: true
- pad_to_sequence_len: true
Using 2 GPUs, the effective global batch size would have been 4.
### Loss graphs
Since the model has been trained with entire samples, loss values are higher than
typical for instruct models or chat models trained on just the model response.
#### Training loss
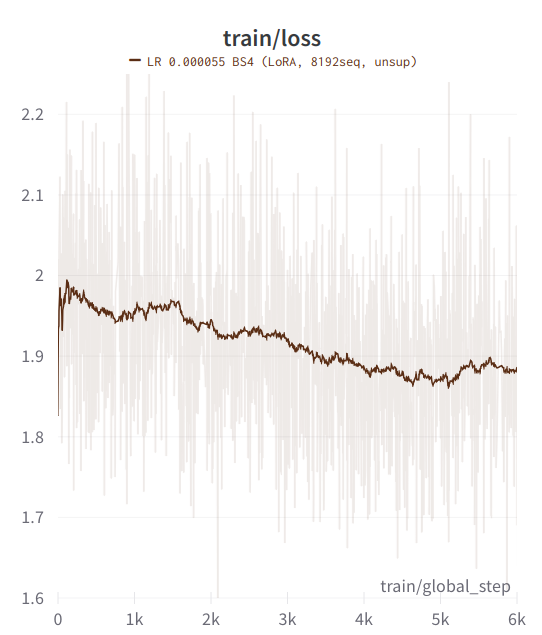
#### Eval loss